Pemrograman CUDA GPU
CUDA adalah platform komputasi paralel dan model pemrograman yang dikembangkan oleh Nvidia untuk komputasi umum pada GPU-nya sendiri (unit pemrosesan grafis). CUDA memungkinkan pengembang untuk mempercepat aplikasi intensif komputasi dengan memanfaatkan kekuatan GPU untuk bagian komputasi yang dapat diparalelkan.
CUDA (Compute Unified Device Architecture) adalah suatu skema yang dibuat oleh NVIDIA agar NVIDIA selaku GPU (Graphic Processing Unit) mampu melakukan komputasi tidak hanya untuk pengolahan grafis namun juga untuk tujuan umum. Jadi, dengan CUDA, kita dapat memanfaatkan cukup banyak processor yang dimiliki oleh NVIDIA untuk berbagai perhitungan. GPU yang ada saat ini seperti ATI pun sudah memiliki banyak processor di dalamnya. Pada ATI, skema yang mereka bangun disebut ATI Stream. Saat ini pemrograman paralel menjadi sangat penting karena kebutuhan kemampuan komputasi komputer yang terus meningkat seperti kemampuan multitasking dan pengolahan grafis yang andal. Metode saat ini dalam peningkatan peforma komputer juga berbeda dengan masa lampau dimana peningkatan clock dari processor yang diutamakan
Parallelism concept
Paralelisme (parallelism) lahir dari pendekatan yang biasa dipergunakan oleh para perancang sistem untuk menerapkan konsep pemrosesan konkuren. Teknik ini meningkatkan kecepatan proses dengan cara memperbanyak jumlah modul perangkat keras yang dapat beroperasi secara simultan disertai dengan membentuk beberapa proses yang bekerja secara simultan pada modul-modul perangkat keras tersebut. Secara formal, pemrosesan paralel adalah sebuah bentuk efisien pemrosesan informasi yang menekankan pada eksploitasi dari konkurensi kejadian-kejadian dalam proses komputasi.Pemrosesan paralel dapat terjadi pada beberapa tingkatan (level) proses. Tingkatan tertinggi pemrosesan paralel terjadi pada proses di antara banyak job (pekerjaan) atau pada program yang menggunakan multiprogramming, time sharing, dan multiprocessing. Multiprogramming kemampuan eksekusi terhadap beberapa proses perangkat lunak dalam sebuah system secara serentak, jika dibandingkan dengan sebuah proses dalam satu waktu, dan timesharing berarti menyediakan pembagian selang waktu yang tetap atau berubah-ubah untuk banyak program. Multiprocessing adalah dukungan sebuah sistem untuk mendukung lebih dari satu prosesor dan mengalokasikan tugas kepada prosesor-prosesor tersebut. Multiprocessing sering diimplementasikan dalam perangkat keras (dengan menggunakan beberapa CPU sekaligus), sementara multiprogramming sering digunakan dalam perangkat lunak. Sebuah sistem mungkin dapat memiliki dua kemampuan tersebut, salah satu di antaranya, atau tidak sama sekali. Pemrosesan paralel dapat juga terjadi pada proses di antara prosedurprosedur atau perintah perintah (segmen program) pada sebuah program.
Distributed Processing
Mengerjakan semua proses pengolahan data secara bersama antara komputer pusat dengan beberapa komputer yang lebih kecil dan saling dihubungkan melalui jalur komunikasi. Setiap komputer tersebut memiliki prosesor mandiri sehingga mampu mengolah sebagian data secara terpisah, kemudian hasil pengolahan tadi digabungkan menjadi satu penyelesaian total. Jika salah satu prosesor mengalami kegagalan atau masalah yang lain akan mengambil alih tugasnya.
Architectural Parallel Computer
SISD
Single Instruction – Single Data. Komputer ini memiliki hanya satu prosesor dan satu instruksi yang dieksekusi secara serial. Komputer ini adalah tipe komputer konvensional. Beberapa contoh komputer yang menggunakan model SISD adalah UNIVAC1, IBM 360, CDC 7600, Cray 1 dan PDP 1.
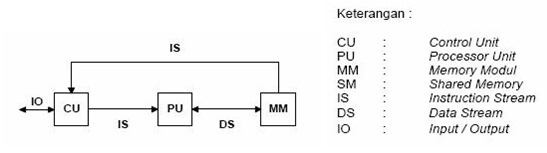
SIMD
Single Instruction – Multiple Data. Komputer ini memiliki lebih dari satu prosesor, tetapi hanya mengeksekusi satu instruksi secara paralel pada data yang berbeda pada level lock-step. Komputer vektor adalah salah satu komputer paralel yang menggunakan arsitektur ini. Beberapa contoh komputer yang menggunakan model SIMD adalah ILLIAC IV, MasPar, Cray X-MP, Cray Y-MP, Thingking Machine CM-2 dan Cell Processor (GPU).
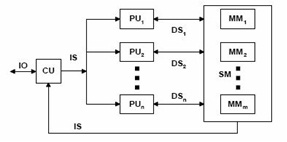
MISD
Multiple Instructions – Single Data. Teorinya komputer ini memiliki satu prosesor dan mengeksekusi beberapa instruksi secara paralel. Sampai saat ini belum ada komputer yang menggunakan model MISD karena sistemnya tidak mudah.
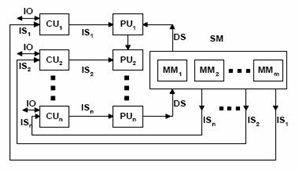
MIMD
Multiple Instructions – Multiple Data. Komputer ini memiliki lebih dari satu prosesor dan mengeksekusi lebih dari satu instruksi secara paralel. Tipe komputer ini yang paling banyak digunakan untuk membangun komputer paralel, bahkan banyak supercomputer yang menerapkan arsitektur ini. Beberapa komputer yang menggunakan model MIMD adalah IBM POWER5, HP/Compaq AlphaServer, Intel IA32, AMD Opteron, Cray XT3 dan IBM BG/L.
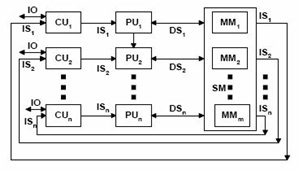
Sistem komputer paralel dibedakan dari cara kerja memorinya menjadi shared memory dan distributed memory. Shared memory berarti memori tunggal diakses oleh satu atau lebih prosesor untuk menjalankan instruksi sedangkan distributed memory berarti setiap prosesor memiliki memori sendiri untuk menjalankan instruksi. Komponen-komponen utama dari arsitektur komputer paralel cluster PC antara lain:
- Prosesor (CPU). Bagian paling penting dalam sistem, untuk multicore terdapat lebih dari satu core yang mengakses sebuah memori (shared memory).
- Memori. Bagian ini dapat diperinci lagi menjadi beberapa bagian penyusunnya seperti RAM, cache memory dan memori eksternal.
- Sistem Operasi. Software dasar untuk menjalankan sistem komputer.
- Cluster Middleware. Antarmuka antara hardware dan software.
- Programming Environment dan Software Tools. Software yang digunakan untuk pemrograman paralel termasuk software pendukungnya.
- User Interface. Software yang menjadi perantara hardware dengan user.
- Aplikasi. Software berisi program permasalahan yang akan diselesaikan.
- Jaringan. Penghubung satu PC (prosesor) dengan PC yang lain sehingga memungkinkan pemanfaatan sumberdaya secara simultan.
Pengantar Thread Programming
Thread dalam sistem operasi dapat diartikan sebagai sekumpulan perintah (instruksi) yang dapatdilaksanakan (dieksekusi) secara sejajar dengan ulir lainnya, dengan menggunakan cara time slice (ketika satu CPU melakukan perpindahan antara satu ulir ke ulir lainnya) atau multiprocess (ketika ulir-ulir tersebut dilaksanakan oleh CPU yang berbeda dalam satu sistem). Ulir sebenarnya mirip dengan roses, tapi cara berbagi sumber daya antara proses dengan ulir sangat berbeda. Multiplethread dapat dilaksanakan secara sejajar pada sistem komputer. Secara umum multithreading melakukan time-slicing (sama dengan time-division multipleks), di manasebuah CPU bekerja pada ulir yang berbeda, di mana suatu kasus ditangani tidak sepenuhnya secara serempak, untuk CPU tunggal pada dasarnya benar-benar melakukan sebuah pekerjaan pada satu waktu. Thread saling berbagi bagian program, bagian data dan sumber daya sistem operasi denganthread lain yang mengacu pada proses yang sama. Thread terdiri atas ID thread, program counter, himpunan register, dan stack. Dengan banyak kontrol thread proses dapat melakukan lebih dari satu pekerjaan pada waktu yang sama.
Karakteristik Thread
Proses merupakan lingkungan eksekusi bagi thread-thread yang dimilikinya. Thread-thread di satu proses memakai bersama sumber daya yang dimiliki proses, yaitu :
• Ruang alamat.
• Himpunan berkas yang dibuka.
• Proses-proses anak.
• Timer-timer.
• Snyal-sinyal.
• Sumber daya-sumber daya lain milik proses.
Message Passing
Massage Passing merupkan suatu teknik bagaimana mengatur suatu alur komunikasi messaging terhadap proses pada system. Message passing dalam ilmu komputer adalah suatu bentuk komunikasi yang digunakan dalam komputasi paralel, pemrograman-berorientasi objek, dan komunikasi interprocess. Dalam model ini, proses atau benda dapat mengirim dan menerima pesan yang terdiri dari nol atau lebih byte, struktur data yang kompleks, atau bahkan segmen kode ke proses lainnya dan dapat melakukan sinkronisasi. Paradigma Message passing yaitu :
1. Banyak contoh dari paradigma sekuensial dipertimbangkan bersama-sama.
2.Programmer membayangkan beberapa prosesor, masing-masing dengan memori, dan menulis sebuah program untuk berjalan pada setiap prosesor.
3. Proses berkomunikasi dengan mengirimkan pesan satu sama lain.

Terdapat beberapa metode dalam pengiriman pesan yaitu :
· Synchronous Message Passing
Pengirim menunggu untuk mengirim pesan sampai penerima siap untuk menerima pesan. Oleh karena itu tidak ada buffering. Selain itu Pengirim tidak bisa mengirim pesan untuk dirinya sendiri.
· Ansynchronous Message Passing
Pengirim akan mengirim pesan kapanpun dia mau. Pengirim tidak peduli ketika penerima belum siap untuk menerima pesan. Oleh karena itu diperlukan buffering untuk menampung pesan sementara sampai penerima siap menerima pesan. Selain itu pengirim dapat pesan untuk dirinya sendiri.
OpenMP (Open Multiprocessing)
OpenMP adalah Application Programing Interface (API) yang mendukung pemrograman multiprosesing shared memory dalam bahasa C/C++ dan fortran pada berbagai arsitektur dan sistem operasi diantaranya: Solaris, AIX, HP-UX,GNU/Linux, Mac OS X, dan Windows.
OpenMP adalah model portabel dan skalabel yang memberikan interface sederhana dan fleksibel bagi programer shared memory dalam membangun aplikasi paralel. Program multithread dapat ditulis dalam berbagai cara. Beberapa diantaranya memungkinkan untuk melakukan interaksi yang kompleks antar thread. OpenMP mencoba untuk memberikan kemudahan pemrograman serta membantu dalam menghindari kesalahan program, melalui pendekatan terstruktur. Pendekatan ini dikenal sebagai model pemrograman fork-join.

OpenMP bekerja berdasarkan model shared memory, maka secara default data dibagi diantara thread-thread dan dapat terlihat dari setiap thread. Terkadang program akan membutuhkan variabel dengan nilai thread spesifik. Jika setiap thread memiliki variabel duplikat akan sangat berpotensi memiliki nilai yang berbeda-beda pada setiap variabel duplikat tersebut.
Sinkronisasi (pengkoordinasian) aksi dari thread adalah sesuatu yang sangat penting untuk menjamin data yang harus dibagi dan untuk mencegah terjadinya data race condition. Secara default OpenMP telah menyediakan mekanisme untuk menunggu thread dalam suatu tim thread sehingga semua thread menyelesaikan tugasnya dalam region, kemudian dapat melanjutkan ke proses selanjutnya. Mekanisme ini dikenal sebagai barrier.
Sumber :
https://general3dent.wordpress.com/2018/05/03/pengantar-pemrograman-cuda-gpu/
https://ind.small-business-tracker.com/what-is-cuda-parallel-programming-648200
http://ridwanraa.blogspot.com/2015/12/parallelism-concept.html
http://muhammadmiftahpratama.blogspot.com/p/pengertian-distributedprocessing.html
https://fikrinm93.wordpress.com/2016/06/17/242/
http://lookoutofme.blogspot.com/2018/06/komputasi-parallel-pengantar-thread.html
http://debelist.blogspot.com/2016/05/parallel-computation-pengantar-message.html